本文共 2136 字,大约阅读时间需要 7 分钟。
在分布式程序架构中,如果我们需要整个体系有更高的稳定性,能够对进程容灾或者动态扩容提供支持,那么最难解决的问题,就是每个进程中的内存状态。因为进程一旦毁灭,内存中的状态会消失,这就很难不影响提供的服务。所以我们需要一种方法,让进程的内存状态,不太影响整体服务,甚至最好能变成“无状态”的服务。当然“状态”如果不写入磁盘,始终还是需要某些进程来承载的。在现在流行的WEB开发模式中,很多人会使用PHP+Memcached+MySQL这种模型,在这里,PHP就是无状态的,因为状态都是放在Memcached里面。这种做法对于PHP来说,是可以随时动态的毁灭或者新建,但是Memcached进程就要保证稳定才行;而且Memcached作为一个额外的进程,和它通信本身也会消耗更多的延迟时间。因此我们需要一种更灵活和通用的进程状态保存方案,我们把这种任务叫做“分布式缓存”的策略。我们希望进程在读取数据的时候,能有最高的性能,最好能和在堆内存中读写类似,又希望这些缓存数据,能被放在多个进程内,以分布式的形态提供高吞吐的服务,其中最关键的问题,就是缓存数据的同步。
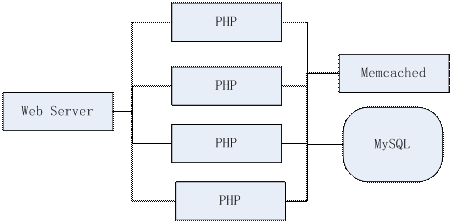
PHP常用Memached做缓存
为了解决这个问题,我们需要先一步步来分解这个问题:
首先,我们的缓存应该是某种特定形式的对象,而不应该是任意类型的变量。因为我们需要对这些缓存进行标准化的管理,尽管C++语言提供了运算重载,我们可以对“=”号的写变量操作进行重新定义,但是现在基本已经没有人推荐去做这样的事。而我们手头就有最常见的一种模型,适合缓存这种概念的使用,它就是——哈希表。所有的哈希表(或者是Map接口),都是把数据的存放,分为key和value两个部分,我们可以把想要缓存的数据,作为value存放到“表”当中,同时我们也可以用key把对应的数据取出来,而“表”对象就代表了缓存。
其次我们需要让这个“表”能在多个进程中都存在。如果每个进程中的数据都毫无关联,那问题其实就非常简单,但是如果我们可能从A进程把数据写入缓存,然后在B进程把数据读取出来,那么就比较复杂了。我们的“表”要有能把数据在A、B两个进程间同步的能力。因此我们一般会用三种策略:租约清理、租约转发、修改广播
租约清理,一般是指,我们把存放某个key的缓存的进程,称为持有这个key的数据的“租约”,这个租约要登记到一个所有进程都能访问到的地方,比如是ZooKeeper集群进程。那么在读、写发生的时候,如果本进程没有对应的缓存,就先去查询一下对应的租约,如果被其他进程持有,则通知对方“清理”,所谓“清理”,往往是指删除用来读的数据,回写用来写的数据到数据库等持久化设备,等清理完成后,在进行正常的读写操作,这些操作可能会重新在新的进程上建立缓存。这种策略在缓存命中率比较高的情况下,性能是最好的,因为一般无需查询租约情况,就可以直接操作;但如果缓存命中率低,那么就会出现缓存反复在不同进程间“移动”,会严重降低系统的处理性能。
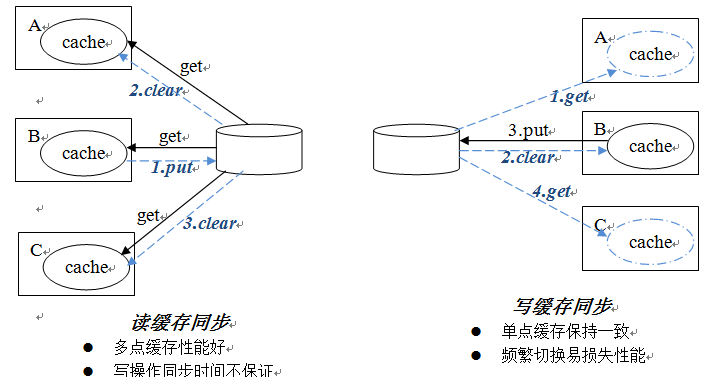
租约转发。同样,我们把存放某个KEY的缓存的进程,称为持有这个KEY数据的“租约”,同时也要登记到集群的共享数据进程中。和上面租约清理不同的地方在于,如果发现持有租约的进程不是本次操作的进程,就会把整个数据的读、写请求,都通过网络“转发”个持有租约的进程,然后等待他的操作结果返回。这种做法由于每次操作都需要查询租约,所以性能会稍微低一些;但如果缓存命中率不高,这种做法能把缓存的操作分担到多个进程上,而且也无需清理缓存,这比租约清理的策略适应性更好。

修改广播。上面两种策略,都需要维护一份缓存数据的租约,但是本身对于租约的操作,就是一种比较耗费性能的事情。所以有时候可以采用一些更简单,但可能承受一些不一致性的策略:对于读操作,每个节点的读都建立缓存,每次读都判断是否超过预设的读冷却时间x,超过则清理缓存从持久化重建;对于写操作,么个节点上都判断是否超过预设的写冷却时间y,超过则展开清理操作。清理操作也分两种,如果数据量小就广播修改数据;如果数据量大就广播清理通知回写到持久化中。这样虽然可能会有一定的不一致风险,但是如果数据不是那种要求太高的,而且缓存命中率又能比较有保障的话(比如根据KEY来进行一致性哈希访问缓存进程),那么真正因为写操作广播不及时,导致数据不一致的情况还是会比较少的。这种策略实现起来非常简单,无需一个中心节点进程维护数据租约,也无需复杂的判断逻辑进行同步,只要有广播的能力,加上对于写操作的一些配置,就能实现高效的缓存服务。所以“修改广播”策略是在大多数需要实时同步,但数据一致性要求不高的领域最常见的手段。著名的DNS系统的缓存就是接近这种策略:我们要修改某个域名对应的IP,并不是立刻在全球所有的DNS服务器上生效,而是需要一定时间广播修改给其他服务区。而我们每个DSN服务器,都具备了大量的其他域名的缓存数据。

总结
在高性能的服务器架构中,常用的缓存和分布两种策略,往往是结合到一起使用的。虽然这两种策略,都有无数种不同的表现形式,成为各种各样的技术流派,但是只有清楚的理解这些技术的原理,并且和实际的业务场景结合起来,才能真正的做出满足应用要求的高性能架构。
转载地址:http://ihuli.baihongyu.com/